Run Langchain Evaluations on data in Langfuse
This cookbook shows how model-based evaluations can be used to automate the evaluation of production completions in Langfuse. This example uses Langchain and is adaptable to other libraries. Which library is the best to use depends heavily on the use case.
This cookbook follows three steps:
- Fetch production
generationsstored in Langfuse - Evaluate these
generationsusing Langchain - Ingest results back into Langfuse as
scores
Not using Langfuse yet? Get started by capturing LLM events.
Setup
First you need to install Langfuse and Langchain via pip and then set the environment variables.
%pip install langfuse langchain langchain-openai --upgradeimport os
# get keys for your project from https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
# your openai key
os.environ["OPENAI_API_KEY"] = ""
# Your host, defaults to https://cloud.langfuse.com
# For US data region, set to "https://us.cloud.langfuse.com"
# os.environ["LANGFUSE_HOST"] = "http://localhost:3000"os.environ['EVAL_MODEL'] = "gpt-3.5-turbo-instruct"
# Langchain Eval types
EVAL_TYPES={
"hallucination": True,
"conciseness": True,
"relevance": True,
"coherence": True,
"harmfulness": True,
"maliciousness": True,
"helpfulness": True,
"controversiality": True,
"misogyny": True,
"criminality": True,
"insensitivity": True
}Initialize the Langfuse Python SDK, more information here.
from langfuse import Langfuse
langfuse = Langfuse()
langfuse.auth_check()Fetching data
Load all generations from Langfuse filtered by name, in this case OpenAI. Names are used in Langfuse to identify different types of generations within an application. Change it to the name you want to evaluate.
Checkout docs on how to set the name when ingesting an LLM Generation.
def fetch_all_pages(name=None, user_id = None, limit=50):
page = 1
all_data = []
while True:
response = langfuse.get_generations(name=name, limit=limit, user_id=user_id, page=page)
if not response.data:
break
all_data.extend(response.data)
page += 1
return all_datagenerations = fetch_all_pages(user_id='user:abc')Set up evaluation functions
In this section, we define functions to set up the Langchain eval based on the entries in EVAL_TYPES. Hallucinations require their own function. More on the Langchain evals can be found here.
from langchain.evaluation import load_evaluator
from langchain_openai import OpenAI
from langchain.evaluation.criteria import LabeledCriteriaEvalChain
def get_evaluator_for_key(key: str):
llm = OpenAI(temperature=0, model=os.environ.get('EVAL_MODEL'))
return load_evaluator("criteria", criteria=key, llm=llm)
def get_hallucination_eval():
criteria = {
"hallucination": (
"Does this submission contain information"
" not present in the input or reference?"
),
}
llm = OpenAI(temperature=0, model=os.environ.get('EVAL_MODEL'))
return LabeledCriteriaEvalChain.from_llm(
llm=llm,
criteria=criteria,
)Execute evaluation
Below, we execute the evaluation for each Generation loaded above. Each score is ingested into Langfuse via langfuse.score().
def execute_eval_and_score():
for generation in generations:
criteria = [key for key, value in EVAL_TYPES.items() if value and key != "hallucination"]
for criterion in criteria:
eval_result = get_evaluator_for_key(criterion).evaluate_strings(
prediction=generation.output,
input=generation.input,
)
print(eval_result)
langfuse.score(name=criterion, trace_id=generation.trace_id, observation_id=generation.id, value=eval_result["score"], comment=eval_result['reasoning'])
execute_eval_and_score()
# hallucination
def eval_hallucination():
chain = get_hallucination_eval()
for generation in generations:
eval_result = chain.evaluate_strings(
prediction=generation.output,
input=generation.input,
reference=generation.input
)
print(eval_result)
if eval_result is not None and eval_result["score"] is not None and eval_result["reasoning"] is not None:
langfuse.score(name='hallucination', trace_id=generation.trace_id, observation_id=generation.id, value=eval_result["score"], comment=eval_result['reasoning'])
if EVAL_TYPES.get("hallucination") == True:
eval_hallucination()# SDK is async, make sure to await all requests
langfuse.flush()See Scores in Langfuse
In the Langfuse UI, you can filter Traces by Scores and look into the details for each. Check out Langfuse Analytics to understand the impact of new prompt versions or application releases on these scores.
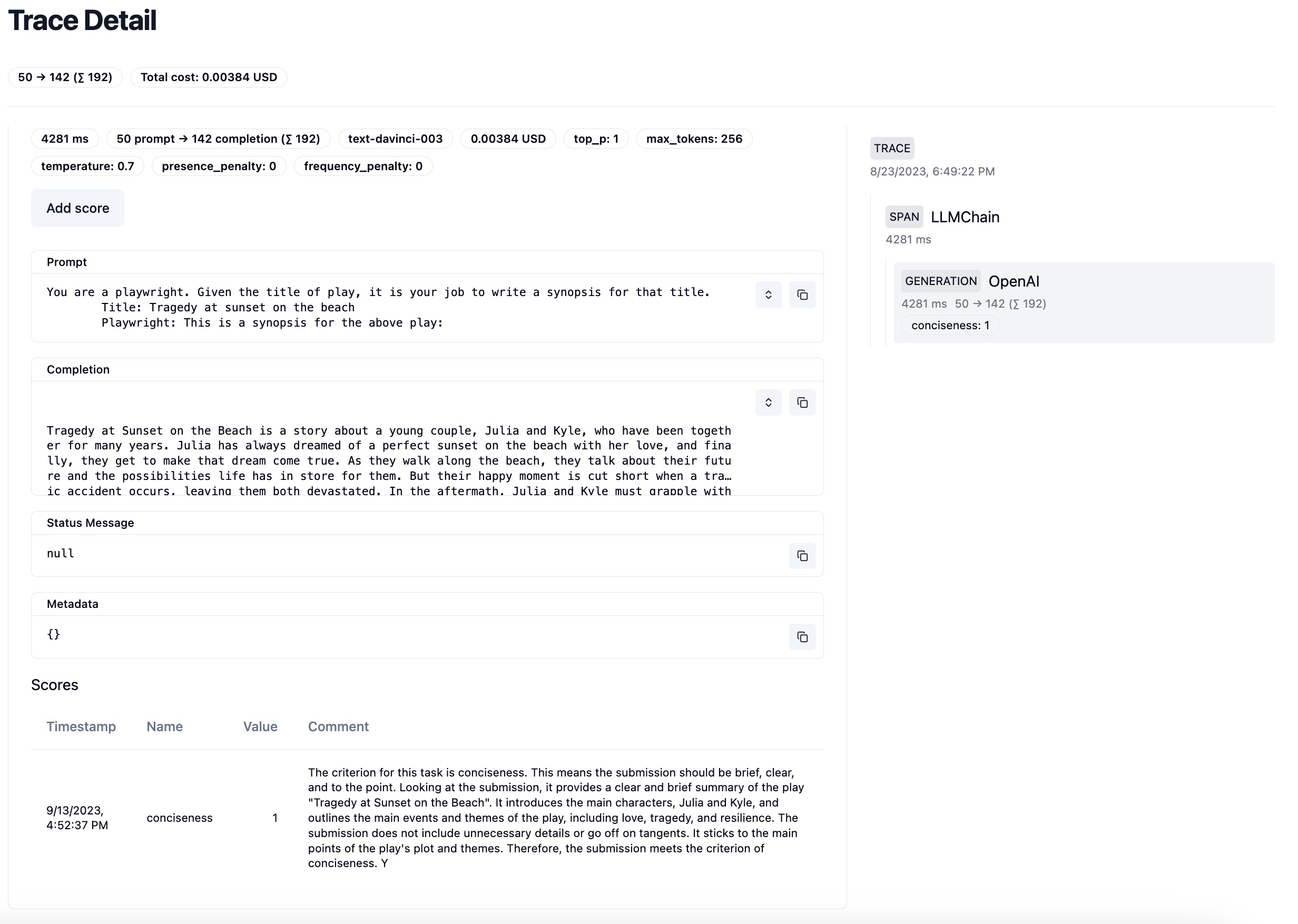 Example trace with conciseness score
Example trace with conciseness score
Get in touch
Looking for a specific way to score your production data in Langfuse? Join the Discord and discuss your use case!